《现代电影技术》丨基于视觉画面的空间音频合成及电影行业应用研究
本文刊发于《现代电影技术》2023年第9期
专家点评
近年来,机器学习、深度学习、人工智能生成内容(AIGC)、人工智能预训练大模型等智能科技在影视行业的发展与应用持续深化和不断泛化。高品质、沉浸式、真实感是电影视听技术发展不懈追求的永恒目标。数字音频空间化在影视领域具有广阔的发展与应用前景,开展音视频联合学习与整体优化是实现数字音频空间化的重要手段和有效方法。《基于视觉画面的空间音频合成及电影行业应用研究》一文提出了一种基于视觉信息的数字音频空间化方法,通过实施基于深度神经网络的声源分离定位和空间音频重构,可实现根据给定视频帧直接将单声道音频转换为沉浸式空间音频,并经实证分析具有一定的有效性和可行性。该方法对于电影沉浸式音频制作具有较好的借鉴意义和参考价值,但目前尚存诸多技术局限性,在电影行业应用仍需在训练数据集构建、系统并行化设计、模型泛化能力等方面实现突破。新时代新征程,人民群众对高品质视听文化产品特别是高新技术格式电影的需求持续增强,立足自主创新,推进自立自强,充分运用现代智能科技手段推动电影作品提质升级和创新发展,对于服务社会主义电影强国建设具有重要的战略意义和现实价值。
——刘达
正高级工程师
中国电影科学技术研究所(中央宣传部电影技术质量检测所)总工程师
《现代电影技术》主编
作 者 简 介

李思佳
天津大学智能与计算学部博士研究生在读,主要研究方向:音视频联合学习。
天津大学智能与计算学部教授,博士生导师,主要研究方向:计算机图形学、视音合成与渲染、虚拟现实等。

刘世光
摘要
新时代电影强国建设对电影技术的发展提出了新要求,创新视听算法和更优模型的自主研发成为人们关注的重点。部分早期影片存储时仅包含单声道音频,不能提供良好的听觉体验。为了解决这个问题,本文提出了一种利用视觉画面和已有单声道音频合成空间音频的方法,重构音频中的空间信息。该方法首先对单声道视频进行声源分离和定位,将其拆解成多个单声源及其位置信息。之后再对其进行空间音频重构,得到与视觉位置信息相一致的更加逼真的音频。实验结果表明,本文方法可以得到与视觉位置信息相一致的更加逼真的空间音频,给用户带来更好的沉浸体验。
关键词
视觉信息;空间音频;声源分离;深度学习;音频空间化
1 引言
科技的发展不断推动电影技术创新,也有力支撑着电影艺术的蓬勃发展。如人工智能(AI)、虚拟现实(VR)等技术,正在逐步改变电影工业的传统工艺并逐步定义着未来的发展方向。科学技术是第一生产力,电影产业技术的自主研发和创新已成为新时代的必然要求。为此,我们需要加强自主创新,站在科技发展的前沿,紧跟科技发展趋势,更好地掌握主动权,促进产业升级,进一步解放和发展生产力,推动电影产业和文化产业高质量发展。
电影效果的呈现不仅依赖于视觉的设计,也离不开听觉、触觉、嗅觉等的应用。与画面匹配的逼真音频可以给用户营造一种更真实的体验,例如,当画面中有一个人从镜头的左侧走到右侧时,同时也应听到从左到右的脚步声,即在镜头左侧时左耳听到更明显的脚步声,走到镜头右侧时则右耳听到更清晰的声音。如果用户在观影过程中能够听到模拟现实中双耳效果的,带有与画面一致的空间感的音频,沉浸感会得到显著提升。
部分早期的影片仅包含单声道音频,用户不易获得很好的听觉体验。当影片仅包含单声道音频时,人的双耳接收到的信息是完全一致的,在不依靠视觉信息的情况下无法辨认声源位置,这显然与现实听感不符,导致整体代入感减弱。我们无法直接将单声道音频转换为双耳音频,因为我们不能凭空添加缺失的空间信息。但在一部电影中,同时拥有画面和声音,视觉和听觉反映了一致的空间信息,因此我们可以利用视觉中的空间信息,对单声道音频进行空间化。
本文将介绍一种视觉信息辅助的音频空间化方法,可以将视频中的单声道音频转换为与画面位置信息相一致的空间音频。该框架输入视频帧和单声道音频,输出对应的具有两个声道的双耳音频,即左右声道分别还原左右耳听到的声音。本文将该任务拆解成两个子任务,即声源分离定位和空间音频重构,缓解了由于空间音频数据集规模较小引发的过拟合问题,实现了在给定视频条件下空间音频的直接合成,提升了用户体验。近年来,AI大模型逐渐成为研究热点,在自然语言[1]、视觉[2]、音频领域[3]以及多模态领域[4]都取得了一定的进展。如果可以将大模型的知识运用到本文特定任务的小模型中,对其效果也将有所提升。
2 国内外研究现状
近年来,基于视觉的音频空间化受到了越来越多的关注。由于我们处理的是视频场景,因此无法直接获得声源及其信息以进行空间音频[5]的渲染。随着深度学习的发展,出现了使用监督学习进行音频空间化的方法,利用数据驱动,隐式地学习音频中的空间信息。
单声道音频缺少空间信息,无法直接进行空间音频的重建,必须借助其他模态,如视觉信号,对其空间信息进行补充。有许多研究者利用将不同的信号与单声道音频相结合,实现单声道音频的空间化。其中Morgado 等人[6]利用全景视频进行辅助,预测不同方向上的声音分量以获得音频的空间信息。虽然全景视频提供了较多的视觉位置信息,但是日常生活中的多数视频并非全景格式,因此其适用范围有限,不直接适用于普通视角的视频。同样基于全景视频进行音频空间化的还有Kim等人[7],不同的是作者估计的是房间的几何结构和声学特性以重建空间音频。类似地,也有利用声学脉冲响应[8]或估计房间的声学材料特征[9]以完成空间音频渲染的相关研究。以上这几种方法仍然有使用场景的局限性,只适用于室内场景,无法拓展到室外的声学场景。
针对普通视角的视频,Gao 和 Grauman[10]采用监督学习的方法来解决这个问题。他们针对此问题采用专业人头录音设备录制了一个双耳声数据集,即FAIR⁃Play数据集,该数据集包含上千段室内乐器演奏的双耳声视频。作者采用UNet网络,输入视频帧和单声道音频,预测双耳声音频。Lu等人[11]同样使用UNet网络作为主干网络,同时在生成网络后添加了一个分类器来完善模型。由于双耳声的左右声道不能互换,因此分类器用来判断生成双耳声的左右声道是否相反,依次进行生成任务和分类任务,以进一步约束模型。Yang等人[12]首先学习空间音频的良好表示,再将空间音频生成作为一项下游任务来进行。同一视频的视觉和音频所包含的空间信息存在一致性,因此作者通过判断音视频特征是否在空间上对齐以学习一个空间音视频的良好表示。这里的空间音频生成作为音视频表示学习的下游任务,两项任务是独立考虑的。与本文密切相关的另一项研究则是视觉辅助的声源分离与音频空间化的多任务学习[13]。该研究将声源分离任务视为一种特殊的音频空间化任务,即将音频分离看作声源分别在最左端和最右端的音频空间化。研究者设计了一种关联神经网络结构以更好地融合视听特征,但这种方法需要引入额外的数据集。
以上讨论的方法都是监督学习的方法,虽然生成效果较好,但也存在一些问题。一方面,现有的可用于监督学习的空间音频数据集较少,数据规模较小,场景也较为局限,多为乐器演奏或室内视频。这使得这类方法很容易产生过拟合问题,泛化性较差,不易推广到其他应用场景。另一方面,空间音频的录制需要一定的成本,录制大规模的数据集较为困难,这也限制了训练出的模型的能力。因此,也有研究者尝试在不依赖此类数据集监督训练的情况下,对给定单声道视频,直接合成相应的空间音频[14]。研究者首先挑选出只有单个声源的视频,并将其裁剪下来,得到画面和声音都只包含一个声源的视频。之后再将这些视频随机粘贴到空间中的不同位置,得到一个新的混合视频。有了声源及其位置,便可以进行空间音频的合成。合成出来的新的空间音视频,又可以作为监督学习数据集的补充,进行数据增强,改善监督学习合成的效果,缓解过拟合问题。但是该方法需要选择单声源数据,这类数据依旧较少。另外该方法在不断创建本来不存在的新数据,而不是直接对给定视频数据进行转换,更类似于一种数据增强方法。
本文旨在介绍一种更加直接的音频空间化方法,将给定的单声道视频转换为空间音频,这里重点关注的是具有左右声道的双耳声。本文将音频空间化任务分成两步执行,即视觉信息辅助的声源分离定位以及空间音频的重构。我们首先训练一个声源分离网络,然后对视频帧沿水平方向进行等距划分,并将每个分区的中心位置作为声源的位置坐标。将这些视频帧输入到训练好的声源分离网络中,得到分离出的声源。有了声源及其位置信息,便可以对其进行空间音频的重构,获得具有空间感的较为逼真的声音效果。
3 音频空间化
我们的双耳能根据听到的声音辨别物体的方位,这种特性也被称为双耳效应,如果在音频制作中模拟这种效果,可以增强观众的听觉体验。人耳可以依据双耳时间差和双耳声级差实现声源的定位,前者是指声音传播到左右耳的时间不同,存在时间差,后者则指左右耳接收到的声音信号强度也有所差异,这些左右耳听到的声音差异就是我们辨别声源方位的依据。在单声道音频中,左右耳接收到的信号完全一致,减弱了沉浸感。如果可以利用电影画面信息作为提示,补全双耳声音信号之间的差异,将会带来更真实的体验。
本章详细介绍将视频的单声道音频转换成空间音频的方法,主要分为两个步骤:声源分离定位和空间音频重构。总体流程图如图1所示,输入视频帧和单声道音频,通过声源分离定位模块得到分离出的多个单声源及其位置信息,之后将其输入到空间音频重构模块,完成音频空间化。具体来讲,对需要进行音频空间化的电影片段,我们首先对其电影画面的视频帧进行提取,然后将电影的单声道音轨分离出来。分别将电影画面帧及音频输入到双流(Two⁃Stream)网络中,实现电影画面的声源分离定位。如电影画面中有两个人物在进行不同的活动,我们将其分割开,并将二人发出的声音也从混合音频中剥离出来。之后我们依据二人的位置重构空间音频,使最终的听感和二人在画面中的位置一致。接下来我们对本文的模块展开介绍。
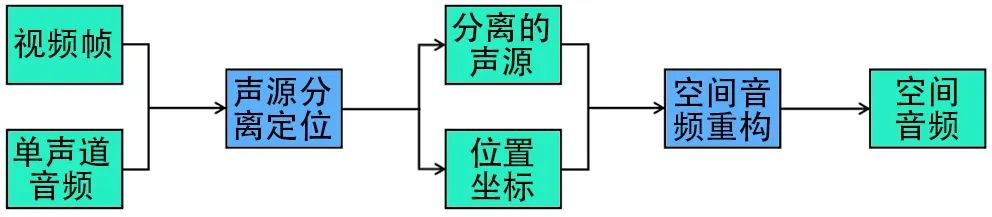
图1 空间音频转换流程
3.1 声音分离定位模块
声音分离定位模块的主要作用是将包含多个声源的音频分离成单个声源的音频,并给出每个声源在画面中的位置坐标。本文将视频画面划分成不同区域,把每个区域视作一个声源,用其中心位置代表其坐标。同时采用混合分离的训练策略[15]训练声源分离网络,将单个声源依据画面分离出来。
声源分离网络采用的是PixelPlayer模型[15],是一个双流处理网络,主要由三部分组成:视频处理模块、音频处理模块以及音频合成模块,如图2所示。
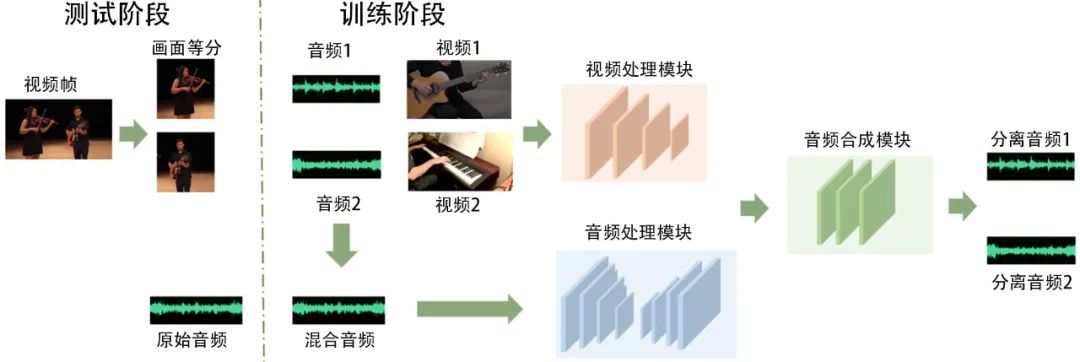
图2 声源分离模块训练和测试示意图
视频处理模块提取每个视频帧中重要的视觉特征,用于指导之后的声源分离。网络的主干结构是带有扩张卷积的ResNet网络,这里采用在ImageNet上预训练的模型初始化其权重。
与视频处理模块相对应,音频处理模块主要作用是分离声音分量。音频网络的架构采用UNet网络,其输入是音频谱图,输出是音频谱图的不同分量,其分量数目和视觉特征的维度相匹配,将原始音频进行分解以便和视觉特征相关联。
最后由音频合成模块实现视听特征的整合,并预测最终分离的输出。视频特征的维度和音频谱图分量的数目相同,可以通过乘法操作将二者进行结合,得到一个和音频谱图大小一致的掩模。该模块预测不同视觉特征对应的声源掩模,得到掩模再和原始混合音频谱图相乘,得到该视觉特征对应的音频谱图,即根据视觉分离出不同的声源。之后利用逆短时傅里叶变换(Inverse Short Time Fourier Transform,ISTFT)将谱图转换回时域即可。
在训练过程中,由于采用的数据集MUSIC⁃21[16]没有标注,因此要构建合适的训练目标。本文采用的是混合分离训练策略[15],随机选取两个视频,将其音频进行混合得到混合音频,网络训练目标是还原这两个视频的原始音频,从而达到学习声源分离的目的。所以训练时网络的输入是两个视频的视频帧以及它们的混合音频,输出是两个视频分别对应的原始音频。通过人为地构造监督条件,可以在无标注数据的条件下,完成声源的分离。
在测试阶段,不再随机选取多个视频混合,而是直接对给定的视频进行处理。考虑到人耳对水平方向上的声音更敏感,因此可以将给定的视频帧沿水平方向进行切分,将其分割成不同的声源。首先将视频帧从中间切分成左右两个部分,将左右两侧看成两个不同的声源。和训练过程相对应,此时待混合的视频变为切分后的两个视频,而混合音频则是原视频对应的音频。将其输入到训练好的网络中后,可以分别得到切分后的视频画面对应的音频。至此,可以从一个混合的声源中分离出两个单独的声源。选取两个分区的中心位置(在原视频中的位置)作为其声源的坐标,完成声源的分离和定位。
在本文中,视觉处理网络利用的是在ImageNet数据上预训练的ResNet网络,也可以考虑将其换成更大规模的模型,如ViT[17]、Swin Transformer[18]等,将其作为主干网络进行特征提取,获得更丰富的视觉特征,不过其对训练资源的要求也会更高。近年来,结合自然语言处理(NLP)领域的大模型也越来越多,尤其是文本和图像的结合[19][20]成为了又一个热点。加入文本模态,用文字提示来辅助对画面的音频分离,或许会是一种更有效的方式。
3.2 空间音频重构模块
通过声源分离定位模块,获得了声源及其位置信息,再将其输入至空间音频重构模块,便可以获得模拟双耳的空间音频。该模块利用高保真环境立体声(Ambisonics)和双耳声重构技术[14],利用多个声源及其位置重构空间音频。
和文献[14]的研究类似,假设声源分布在一个球面上。不同的是,本文旨在对给定的单声道进行直接的空间音频转换,在转换过程中不再创建新的视频。本文将画面划分成不同的区域,每个区域看作一个抽象的声源,不再利用目标检测对画面进行裁剪,因为其非常依赖于目标检测器的精度。声源的位置坐标也不再是随机生成,而是计算每个区域的中心位置坐标进行近似。另外文献[14]要求选取的是单声源视频,数据要求较高,本文通过添加声源分离定位模块避免了这个问题。
由于假设声源分布在球面上,首先要进行坐标系的转换。将平面直角坐标转换到球面坐标,从而将声源映射到球面上,即:

得到球面坐标后,可以利用Ambisonics技术进行空间音频的重建。将声源映射到球面后,利用球谐函数分解来对空间音频进行描述。如果声源的入射方向为[Ω=(θ,ϕ)],则球谐函数可以用式(2)表示:
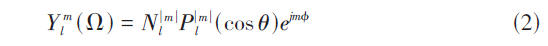
其中m是阶数,l是次数,Pml则是伴随勒让德多项式,Nml是归一化常数,采用的是施密特正交化。球谐函数可以作为基函数,因此一个给定的从Ω方向入射的声音信号可以用式(3)表示:
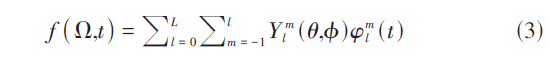
其中L是最高次数,φml是对应的系数。每一项的系数都可以根据声源及其位置信息计算出来。因此,只要在声源分离定位模块计算出声源和位置,就可以实现空间音频的重构。本文只考虑一阶Ambisonics的情况,即有四个方向上的声道:全向、x方向、y方向以及z方向 ,每个方向对应的系数同样可以通过声源及其所在位置计算出来。
之后我们只需将其转换成双耳声即可,这里需要利用头相关脉冲响应(Head⁃Related Impulse Response, HRIR)。先将信号分解成N个不同方向上的虚拟声源,利用其球谐函数将其求解出来。求解出的虚拟声源再和HRIR进行卷积,由于双耳声有两个声道,分别进行卷积得到左耳和右耳对应的声音:
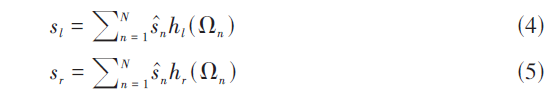
其中hl和hr分别是左耳和右耳对应的HRIR,ŝn是虚拟声源。
4 实验结果与分析
本章主要介绍实验所用的数据集,并对不同模块的结果进行展示,以表明其有效性。针对电影画面,我们首先将其切割成视频片段,然后对每个片段进行抽帧,并分离出单声道音轨。再将得到的电影片段视频帧及单声道音频按照第三章的方法进行处理,即可得到具有空间音频效果的电影片段。
4.1 实验数据集
在声源分离定位模块,本文采用MUSIC⁃21数据集[16],其是视觉辅助的声源定位领域常用的数据集之一。它对数据集MUSIC[15]进行补充,原始数据集包括714个乐器演奏视频,涵盖11种乐器,分别为:手风琴、原声吉他、单簧管、长笛、大提琴、萨克斯管、大号、小号、二胡、小提琴和木琴。通过查询乐器名加演奏扩充后,MUSIC⁃21[16]共收集了1365个YouTube上的乐器演奏视频,多为独奏或二重奏,涵盖21种乐器,与之前相比新添加了以下10种常见的乐器:电贝斯、风笛、康佳鼓、班卓琴、古筝、巴松管、钢琴、鼓、琵琶和尤克里里。该数据集没有额外的标注,其中1065个视频用于训练集,300个视频用于测试集。
在空间音频重构模块,本文采用的是CIPIC HRTF数据集[21]。这是一个实验测量得到的头相关传输函数(Head Related Transfer Function,HRTF)数据集。在空间音频重构模块中,本文利用了头相关脉冲响应(HRIR),其正是HRTF的时域表示。将声源分离定位模块得到的单声源与头相关脉冲响应(HRIR)进行卷积,得到模拟的双耳声。也可以先对声源信号进行傅里叶变换,再与头相关传输函数(HRTF)做乘积得到双耳声。该数据集记录了45名受试者的相应数据,其中共有男性27人,女性16人。其中音频的采样率为44.1kHz,16比特位深。头相关脉冲响应(HRIR)的长度约为4.5毫秒,大约200个样本点。该数据集在半径1米的1250个方向上进行测量,同时也包含了受试者的身体测量数据。该数据集是常用的HRTF数据集之一,可以利用它实现对双耳声较好的模拟重现。
4.2 声源分离结果
给定一个视频帧,往往存在多个同时发声的声源,声源分离定位模块旨在根据画面内容将其分解成多个单声源音频,本节展示该模块的分离结果,验证其有效性。对于声源分离网络,训练和测试阶段的输入有所差异。在训练阶段,输入在数据集中任选的两个独奏视频的视频帧及其混合音频。在测试阶段,则只选取了数据集中任意一个二重奏视频的视频帧及其音频作为输入。将视频帧沿水平方向分割裁剪,再将这些分割后的视频输入到网络中,得到每个分区对应的声音。之后再分别计算其中心坐标作为声源的位置信息。
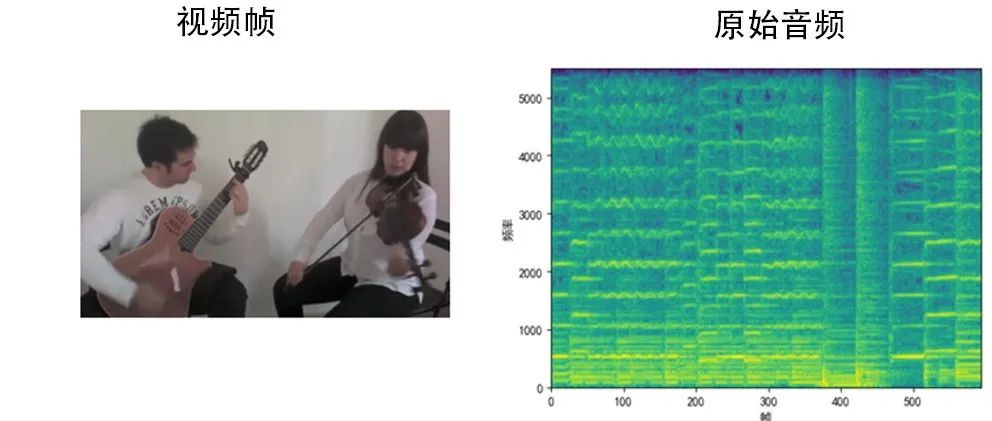
部分分离结果如图3所示。展示的例子中存在两个声源,分别是左侧的吉他和右侧的小提琴。可以从其音频谱图中看出,两种声源混叠在一起,难以直接从谱图中进行区分。图3中下面两图是将该视频帧从中间等分裁剪后分别输入至网络得到的结果。可以看出网络根据图像内容将声源较好地分离出来,从混合音频中成功分离出来画面左侧的吉他声音以及画面右侧的小提琴声音,验证了声源分离定位模块的有效性。
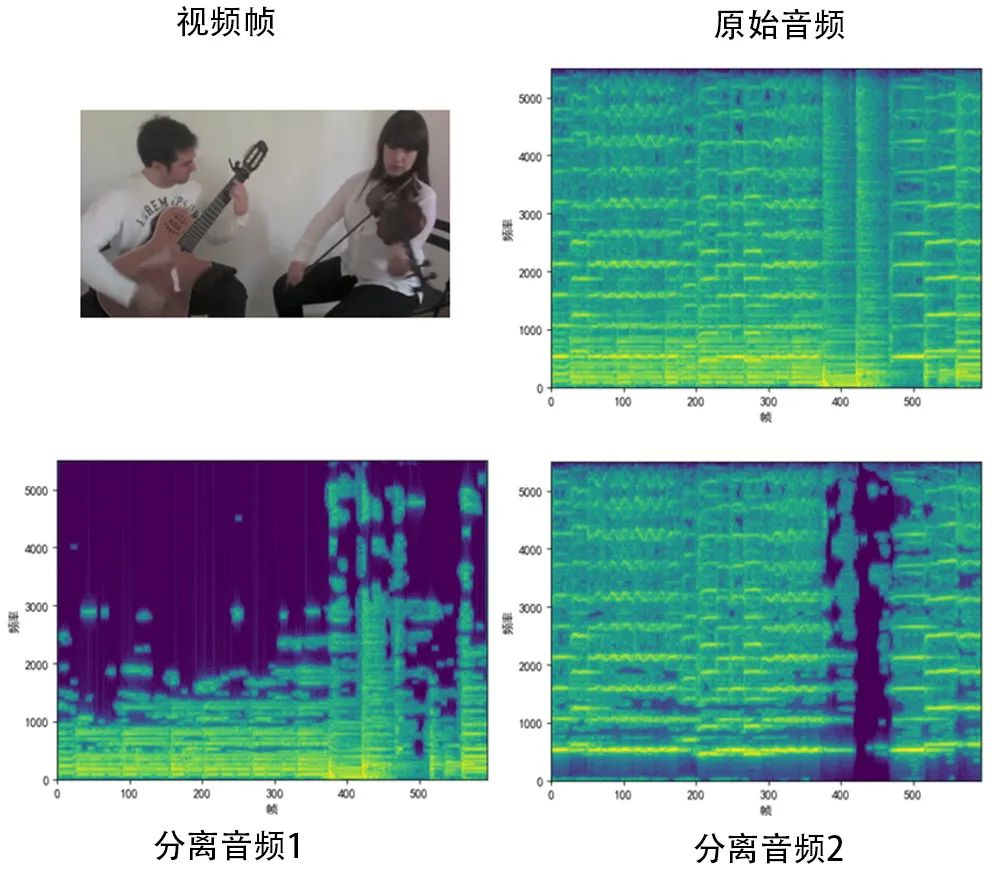
图3 声源分离结果展示
4.3 空间音频重构结果
有了声源分离和定位的结果,将其输入到空间音频重构模块,模拟现实中的双耳声效果。如果我们获得分离出的声源后,只是简单地将它们分别分配给左右声道,这显然是不符合实际的。因为人的左耳不止能听到画面左边的声音,也能听到画面右边的声音,只是接收到的声音信号的时间和强度存在着一些差异。因此我们必须根据其在画面中的位置进行重构,而这正是声源分离定位模块的输出。
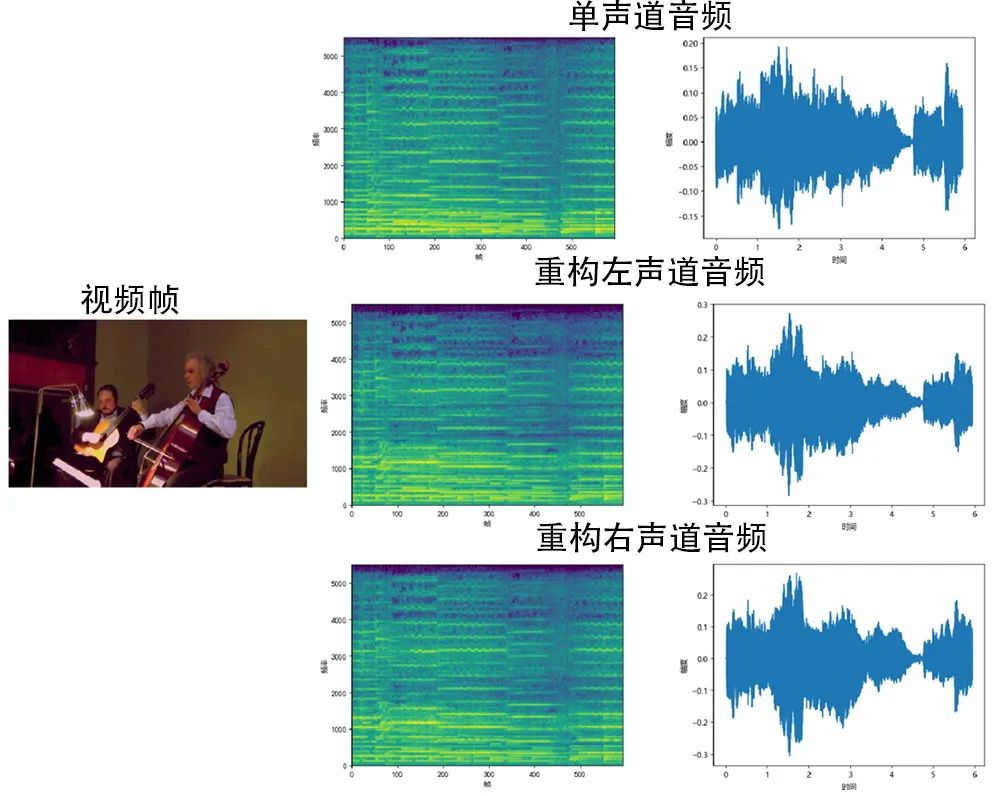
图4 音频空间化结果展示
部分重构后的空间音频结果如图4所示。由于本文重建的是双耳声,所以重建结果中有两个声道,分别对应左右耳的声音。从图4中可以看出,空间音频重构模块将两种声源重新进行组合,获得了模拟双耳声的效果。左右两个声道的谱图非常接近,但又存在着细微差异,既不会像单声道音频左右耳听到完全一样的声音,也不会像将声源简单地分配给左右声道而听到完全不同的声音。当佩戴耳机时可以感受到与画面一致的有空间感的音频,验证了空间音频重构模块的有效性。
5 结语
本文介绍了一种视觉信息辅助的音频空间化方法,可以根据给定的视频帧直接将其单声道音频转换为空间音频。该方法包括声源分离定位和空间音频重构两个模块。首先训练一个声源分离定位网络,然后将给定的视频帧按水平方向进行等区域划分,将划分后的区域看作单独待分离的声源输入进训练好的网络,得到对应的音频。分别取其中心位置作为声源坐标,编码得到Ambisonics音频,再利用头相关脉冲响应(HRIR)解码成双耳声。相比单声道音频,采用本文方法的结果具有更强的空间感,能给用户带来更加沉浸的体验,可应用到电影沉浸式音频的制作。由于存储方式或压缩等其他因素的影响,部分电影只留下了单轨音频,当观众再次观看时不能获得良好的体验。通过本文方法将其转换为空间音频后,可以尽力还原沉浸式的音频体验。
本文方法依然有许多局限性,在未来的工作中仍有待改进。本文方法将音频空间化拆成两个子任务并顺序执行,导致后一个任务对前一个任务有着较强的依赖性。如果声源分离的效果较差,则在后一步也很难渲染出具有真实感的双耳声。例如当画面中存在两个相似的乐器时,很难完美地将其分离开。另外在此过程中可能会引入噪声,导致最终高频细节缺失,影响音频听感。在本文中没有考虑运动信息,但声音是由物体振动产生的,对运动的描述有利于更好地重构声音,这也是未来值得研究的工作。此外,如何进一步提高模型的泛化性,使其能更好地应用到现实世界的视频中,也是未来需要考虑的方向。对AI大模型的融入或许是一个解决方法,AI大模型在大规模数据集上进行训练,可以引入一些额外的先验知识,在一定程度上可以缓解部分泛化性问题。另外利用大语言模型(LLM)将文本模态引入,利用文本提示来进行空间化的辅助,也是一个研究方向。
未来我们需要自主提出更多的创新算法,弥补现有不足,并将创新技术应用到实际中,理论结合实践,努力实现电影科技自立自强,为电影强国的建设添砖加瓦。同时也要捕捉科学技术发展的新趋势,站在科技发展前沿,研发先进的视听技术,推动电影产业的持续发展与提质升级。
参考文献
(向下滑动阅读)
[1] Brown T, Mann B, Ryder N, et al. Language models are few⁃shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877⁃1901.
[2] Han K, Wang Y, Chen H, et al. A survey on vision transformer[J]. IEEE transactions on pattern analysis and machine intelligence, 2022, 45(1): 87⁃110.
[3] Zhang Z, Zhou L, Wang C, et al. Speak foreign languages with your own voice: Cross⁃lingual neural codec language modeling[EB/OL]. (2023⁃03⁃07).https://arxiv.org/abs/2303.03926.
[4] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748⁃8763.
[5] 谢菠荪. 空间声原理 [M]. 科学出版社, 2019.
[6] Morgado P, Nvasconcelos N, Langlois T, et al. Self⁃supervised generation of spatial audio for 360° video [C]. In Proceedings of the Advances in Neural Information Processing Systems, 2018: 362⁃372.
[7] Kim H, Hernaggi L, Jackson P J, et al. Immersive spatial audio reproduction for VR/AR using room acoustic modelling from 360°images [C]. In Proceedings of the IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 2019: 120⁃126.
[8] Li D, Langlois T R, Zheng C. Scene⁃aware audio for 360° videos [J]. ACM Transactions on Graphics (TOG), 2018, 37 (4): 1⁃12.
[9] Tang Z, Bryan N J, Li D, et al. Scene⁃aware audio rendering via deep acoustic analysis [J]. IEEE Transactions on Visualization and Computer Graphics, 2020, 26 (5): 1991⁃2001.
[10] Gao R, Grauman K. 2.5D visual sound [C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 324⁃333.
[11] Lu Y, Lee H, Tseng H, et al. Self⁃supervised audio spatialization with correspondence classifier [C]. In Proceedings of the IEEE International Conference on Image Processing (ICIP), 2019: 3347⁃3351.
[12] Yang K, Russell B, Salamon J. Telling left from right: learning spatial correspondence of sight and sound [C]. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9932⁃9941.
[13] Zhou H, Xu X, Lin D, et al. Sep⁃stereo: visually guided stereophonic audio generation by associating source separation [C]. In Proceedings of the European Conference on Computer Vision, 2020: 52⁃69.
[14] Xu X, Zhou H, Liu Z, et al. Visually informed binaural audio generation without binaural audios [C]. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 15485⁃15494.
[15] Zhao H, Gan C, Rouditchenko A, et al. The sound of pixels [C]. In Proceedings of the European Conference on Computer Vision (ECCV), 2018: 570⁃586.
[16] Zhao H, Gan C, Ma W⁃C, et al. The sound of motions [C]. In Proceedings of the IEEE International Conference on Computer Vision, 2019: 1735⁃1744.
[17] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL].(2021⁃06⁃03). https://arxiv.org/abs/2010.11929.
[18] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision,2021: 10012⁃10022.
[19] Li J, Li D, Xiong C, et al. Blip: Bootstrapping language⁃image pre⁃training for unified vision⁃language understanding and generation[C]//International Conference on Machine Learning. PMLR, 2022: 12888⁃12900.
[20] Li J, Li D, Savarese S, et al. Blip⁃2: Bootstrapping language⁃image pre⁃training with frozen image encoders and large language models[EB/OL]. (2023⁃06⁃15).https://arxiv.org/abs/2301.12597.
[21] Algazi V R, Duda R O, Thompson D M, et al. The CIPIC HRTF database [C]. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics, 2001: 99⁃102.
【本文项目信息】国家自然科学基金项目《水下声音传播的真实感模拟关键技术研究》(62072328)。
