《现代电影技术》|视听同步的细粒度脚步音效合成方法

本文刊发于《现代电影技术》2023年第12期
专家点评
过去二十多年,电影的数字化为电影产业的发展进步提供了强大的技术支撑;今天,智能化升级将成为数字化以来电影行业发展提质的又一次重大技术变革。电影智能制作手段已经开始应用于电影声画制作的各个环节,不断提高电影的生产能力和效率。近年来,视听领域的智能音效生成工具层出不穷,其利用人工智能技术自动化音效的制作过程,通过机器学习模型的训练调优,让计算机自动从音效库中选取最优的声音素材进行音效的实时合成。但迄今为止,这些工具尚无法达到电影制作的要求,行业需要一款达到电影制作标准的智能音效制作工具来提高制作效率。《视听同步的细粒度脚步音效合成方法》一文正是针对上述问题做出了有效的探索,提出了一种高质量脚步音效的自动合成方法,其充分利用画面多种信息,通过自建数据集训练,实现声画同步且真实的脚步音效合成,最后进行了实验验证,取得了较好的效果。相信未来电影音效的智能制作会得到更广泛的应用,但是当前还要彻底解决画面元素和对应声音元素的精准对位问题、声音真实感问题,当然这不仅仅只包含脚步声,而是包含电影画面和声音创作更为丰富的构成元素,只有这样智能音效工具才能成为电影声音制作的真正利器,极大地提高生产能力和效率。
——陈军
研究员
北京电影学院影视技术系主任
作 者 简 介

刘子航
中国传媒大学数据科学与智能媒体学院大学本科在读,主要研究方向:智能影像工程。
中国传媒大学融媒体国家重点实验室博士研究生在读,主要研究方向:音效合成技术、跨模态音频生成。

齐秋棠

程皓楠
中国传媒大学融媒体国家重点实验室副研究员,主要研究方向:音频仿真、音频信号处理。
新华通讯社高级工程师,主要研究方向:视频处理技术、人工智能技术应用等。

崔 健

叶 龙
中国传媒大学数据科学与智能媒体学院院长,融媒体国家重点实验室研究员,主要研究方向:智能音视频处理技术、虚拟现实技术。
摘要
电影后期音效制作合成目前仍主要依赖手动操作,其人力与资源成本较高。现有智能拟音技术由于存在合成声音缺乏细粒度内容和真实感不足等问题,难以满足实际电影后期音效制作要求。针对上述问题,本文提出了一种细粒度脚步音效的自动合成方法,充分利用视觉画面信息,以实现视听同步且内容匹配度高的脚步声音效合成。具体而言,本文采用数据驱动的视听跨模态生成方法,深入学习视听时序关联,以实现视听同步。随后,为了进一步丰富合成脚步声音的内容细粒度,对视觉画面中的地面材质和人物运动信息进行深入分析,并构建与声音之间的规则连接。实验证明,本文的方法能够合成与视觉信息匹配的时间同步且内容合理的脚步音效,实现了脚步音效的自动化生成,提升了视听的真实感。
关键词
电影音效制作;智能化拟音;脚步音效合成;跨模态视听生成
1 引言
电影作为主流多媒体作品形式之一,主要从视觉与听觉两个方向与观众产生感知上的交互。音效作为电影后期制作声音设计的核心,在从听觉方向增强电影的故事叙述以及观众的真实感、沉浸感等方面发挥了至关重要的作用。由于电影拍摄场景的声音环境可控性受限以及其他因素的影响,直接录制背景真实音效是困难的。在实际电影播放的场景中,影片中的脚步声等音效是影响电影场景氛围感与真实感的关键性因素。因此,在电影拍摄制作过程中,通常会通过使用音效库素材后期混音或直接进行拟音实现影片中的脚步声、摩擦声等动效(由人物所发出的非对白声音)声音设计与合成,而这项工作需要经验丰富的声音设计师耗费大量时间和资源来完成。
在实现各种关键性动效声音的拟音过程中,脚步声是每个电影后期拟音的初始阶段都需要面对的,这也是拟音师们进行声音设计的基本功。不同的地面材质、鞋子类型、人物的重量以及步伐的差异都会影响脚步声音的真实感与契合度。即使是专业拟音师,在拟音过程中想要同时保证声音与视觉画面时间保持同步且内容保持一致性都是一项不小的挑战。
随着机器学习(Machine Learning)、深度学习(Deep Learning)、人工智能(AI)等现代智能科技的持续发展和不断深化,为影视行业带来新的机遇,也为电影音效设计的智能化提供了新的思路。深度学习方法提供了高强度算力、庞大数据量以及深层次模型,为视觉与声音关系学习提供了基础支撑。然而,大数据量驱动的方法难以实现细粒度的内容控制和视听细粒度关系的映射对应,因此导致合成的音效缺乏内容细节区分,进而造成真实感和沉浸感的不足。
本文提出了一种细粒度脚步音效的自动合成方法。该方法融合了数据驱动与规则建模方法,有效地构建了不同视觉线索与模拟声音的映射关系,利用数据驱动方法实现视听时序一致,利用规则建模方法细粒度地控制声音合成,以智能化拟音技术解决视觉与声音的同步性以及内容一致性的问题。实验证明,本文的方法能够实现脚步音效的自动化生成,并且合成的脚步音效与视觉画面之间在同步性及内容一致性方面均有较好结果。智能化音效合成工作不仅能有效增强观众沉浸感与电影作品的真实感,也能改善人工拟音工作的人力与资源压力。
2 国内外研究现状
随着科学技术水平的不断提升,电影行业逐渐出现了各种先进的声音合成方法。现阶段,视觉引导的声音合成工作可分为三类:手工拟音的方法、基于规则的建模方法和数据驱动的方法。
手工拟音是一种传统的电影后期音效制作方法,拟音师通过手动操作为电影进行后期音效配音。这包括使用各种道具和动作来产生合适的拟音效果以匹配电影画面(例如在粗糙的表面上用力奔跑,相互推动,擦洗不同的道具),从而达到后期拟音补充视觉画面的效果。然而,手工拟音存在人力和资源高成本的挑战,因此,智能化的后期音效合成工作将成为电影行业的发展趋势。在智能化拟音技术的发展中,视觉与声音的同步性和内容一致性是需要解决的关键难点,这对于电影的真实感和观众的沉浸感有重大影响。
基于规则的声音合成方法包括基于信号和基于物理的合成方法。基于信号的合成方法[1][2][3]采用运动、纹理、频谱等信号信息进行分析和建模,以实现声音合成。但该类型的方法需要手动控制且难以与视觉画面同步。相比之下,基于物理的合成方法[4][5][6][7]则对物体振动进行建模,并通过声学方程来计算声压,以实现声音合成。该类方法能够合成高细粒度的声音,通常用于动画场景配音。然而,对于实际电影场景,该方法依赖的视觉参数难以通过物理建模获取,因而难以适用于电影后期音效合成。
数据驱动的方法利用神经网络通过学习大量视音频数据的同步映射关系自动实现声音合成。这种方法提供了新的声音合成思路。尤其近年来大数据和大模型的推动,涌现出了一批优秀的研究,例如:RegNet[8]、V2RA⁃GAN[9]、SpecVQGAN[10]、AutoFoley[11]、FoleyGAN[12]、SPMNet[13]等。然而,数据驱动方法缺乏细粒度表征和明确的映射关系,这些方法无法实现类内细粒度的声音合成,对电影的视觉补充效果不佳,尤其在脚步声音合成方面的细粒度控制方面存在挑战。视觉引导的声音合成技术有望进一步改进和发展,以提高声音合成的质量、精度和真实感。
3 细粒度脚步音效合成方法
本章详细介绍了视觉引导的细粒度脚步音效合成方法,其主要由视听时序同步的脚步音效合成、脚步音效内容细粒度优化两个部分组成。整体的框架结构如图1所示,输入无声视频,通过音效生成以及细粒度优化合成与视频中人物运动一致的脚步音效。具体而言,首先该方法利用视听生成网络,学习视听关联,合成与视觉画面同步的脚步音效,保证视觉和声音之间的时序一致性。为了进一步提高声音真实感,实现脚步音效的细粒度差异变化,我们将通过内容细粒度优化模块对音效进行调整。
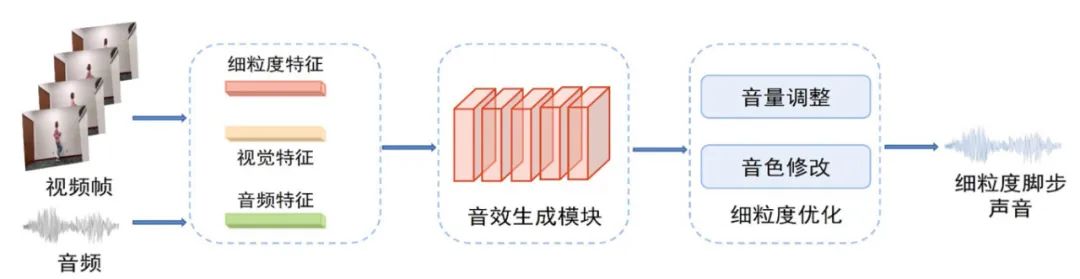
图1 细粒度脚步音效合成框架
3.1 数据驱动的音效生成网络
实现还原度高的脚步音效合成的第一步是满足视听同步。为获取视听同步的关键性信息,解决视觉与音频间同步性问题,本文设计了一个音效生成模块。该模块利用深度学习网络进行视听关系的学习以及脚步音效的合成。图2阐释了本节中所提到的模块具体结构。该模块由视觉编码器、声音编码器、声音生成网络和声码器四部分组成。

图2 数据驱动音效生成网络框架
特征的选择对视觉与声音的编码尤为重要,为了获取足够丰富的视觉信息以及声音信息,我们首先对视觉与声音进行特征提取,其中视觉特征选择RGB特征、光流特征以及人物姿态特征,音频特征选择Mel频谱特征。紧接着,将提取的视觉特征与声音特征分别送入到视觉编码器以及声音编码器中,为了更好地捕捉双向长距离视听依赖关系,我们选择了双向长短时记忆网络(Bidirectional Long Short⁃Term Memory, BiLSTM)[14]作为编码器。将视觉与声音编码特征对齐拼接后,送入声音生成网络进行处理。
声音生成网络架构采用生成式对抗网络(Generative Adversarial Network, GAN)[15],通过网络学习视听时序关系,并进行声音频谱生成。生成式对抗网络包括一个生成网络G以及一个判别网络D,两个网络通过相互对抗博弈的方式进行训练。生成网络通过学习训练集数据的特征,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成声音频谱。而判别网络则负责区分输入的声音频谱是真实的还是生成网络生成的假数据,并反馈给生成网络。两个网络交替训练,能力同步提高,直到生成网络生成的数据能够以假乱真,并与判别网络的能力达到一定均衡。
在训练过程中,生成网络试图最小化损失函数如式(1)所示:

式(1)中,第一项是L2重构误差,第二项是对抗损失, Fs、Fv以及Fc分别表示编码后的音频特征、视觉特征以及视听融合特征。与之对应,判别网络同样需要最小化损失函数如式(2)所示:
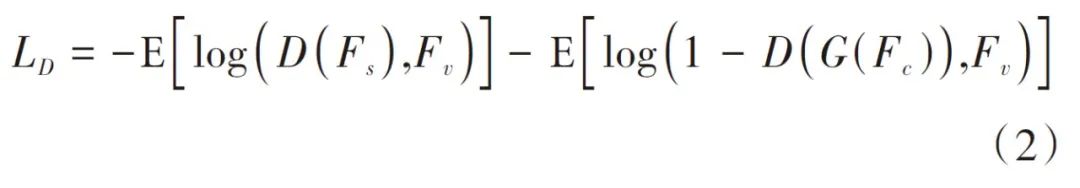
声音生成网络生成的声音频谱在经过声码器之后重构为声音波形。常用的声码器包括基于信号处理的声码器如Griffin⁃Lim算法[16],以及基于神经网络的声码器如WaveNet[17]、MelGAN[18]。本文中声码器选择了预训练的WaveNet[17]。但随着近年来神经网络声码器的迅速发展,声码器也可考虑更新为HiFiGAN[19]等更优秀的网络。经过数据驱动音效生成网络,可以实现视听同步。
3.2 脚步音效的内容细粒度优化
在实现了脚步声视听同步的基础上,为提高脚步声的还原度,需要保证视听内容的细粒度一致。在本文的音效生成网络部分仅实现了视觉画面与声音的同步性。但无法实现更细粒度的差异区分,这将导致其难以在实际电影后期拟音中使用。为了实现基于视觉线索的细粒度声音控制目标,获得更真实的声音,本文设计了内容细粒度优化模块,对脚步音效内容进一步完善。
地面材质和人体运动特征是脚步声中两个重要的不变量。首先,地面材质对脚步声音具有显著影响。不同的地面材质会导致脚步声音产生不同的音质特性。比如,走在混凝土地面和走在木地板上会产生截然不同的脚步声,前者可能更为沉闷,而后者可能更为清脆。因此,考虑地面材质对声音的影响对于脚步声合成至关重要。其次,人体运动特征也是影响脚步声的重要因素。不同的人体运动方式,比如行走、奔跑、跳跃等,会产生不同的脚步声音。这种声音的变化可以通过调整声音的频率、响度和节奏等参数来模拟,以使其与特定的人体运动特征相匹配。因此,考虑地面材质和人体运动特征作为脚步声合成的两个不变量,可以使得合成的脚步声更具真实感和逼真度。
针对上述分析,本文设计的内容细粒度优化模块由两部分组成:(1)基于视觉地面材质的音色修改;(2)基于视觉运动分析的响度调整。图3阐释了本节中所提到的模块具体结构。
图3 脚步音效的内容细粒度优化框架
3.2.1 基于视觉地面材质的音色替代模型
观众在观看电影中的场景时,会受到人物行走时地面材质声音的反馈影响,从而影响他们对场景真实度的感知。为了确保音色与视觉地面材质之间的一致性,并提升生成声音的真实性和细节,本文设计了音色替代模型,用于修改和替换音色。
为了在保持效率和分类速度的前提下,实现对视觉地面材质的识别和标记,本文采用了EfficientNet[20]作为地面材质识别网络,将视频帧输入材质分类网络,输出得到视觉地面材质标签,如混凝土、瓷砖、地毯等。然后,通过发声点检测器获取数据驱动音效生成模块生成的脚步声的发声时间。发声点检测器利用光谱通量作为检测密度,通过峰值检测和自适应阈值方法获得起始点的时间序列。
随后,我们将视觉地面材质标签和检测到的脚步发声时间序列输入音色修改模型中,根据视觉地面材质标签从声音样本库中检索相应的脚步声音样本,利用脚步发声时间序列保证视听同步不发生改变,进而完成音色替代和修改。这个方法可以根据不同的地面材质来调整脚步声的音色,保证了脚步声的音色与视觉地面材质的一致性,增强了声音的真实感。
3.2.2 基于视觉运动分析的响度调整
基于视觉运动分析的响度调整是实现脚步声细粒度控制的重要步骤。在这个过程中,我们关注声音的响度,这是影响场景画面中声音真实度的关键因素。首先,我们提取声音的包络,以便调整合成声音的响度。包络提取采用了非线性低通滤波器,如式(3)所示:

当x(n)>e(n-1)时,b(n)取值0.8,其他情况下b(n)取值0.995。其中,n和n-1表示当前和前一个样本的离散变量。
为了实现细粒度的响度控制,我们分为两个层次对脚步音效进行调整,分别是全局位移、动作类型,这样的分级允许我们从宏观到微观进行控制,以获得更精准的响度调整。
(1)全局位移层:这一层级是宏观控制的基础,基于整体的位移曲线可以控制整体响度幅度和衰减。人在视觉画面中的位置随着时间的推移而变化,因此脚步声的响度也应该相应变化。由于缺少相机标定,直接获取视觉场景中人物位移变化尤其困难,但可以通过视觉运动中人物轮廓的大小来估计。在视觉画面中,人物轮廓面积越大,距离越近,则脚步声音越大,反之亦然。因此,通过对人物轮廓面积进行序列分析和曲线拟合,可以得到人物位移时间变化曲线,其作为宏观响度的激励因素实现响度的全局调整。
(2)动作类型层:在这一层级,我们根据动作类型对响度进行微观控制。通过划分不同动作类型,可以更细致地调整声音的响度,使其更逼真。一般来说,脚步动作分为走、跑、跳三类,不同动作类型对应不同的响度阈值。为实现基于动作的响度调整,本文对视觉的顺序动作进行了定位,并将画面中人物的动作划分为间隔动作。如果同一视频中有两种或两种以上的动作,我们会根据动作类别对应的响度阈值来调整响度;如果在同一视频中没有明显的动作差异,则不进行处理。
通过细粒度的控制和调整,我们可以更好地匹配声音与视觉运动的特性,以实现更真实和逼真的脚步声。这种结合了宏观和微观层次的响度控制,使声音更贴近真实场景中的表现,提升了脚步声的真实感和逼真度。该方法能有助于提高电影的音频质量,使观众更好地融入电影情节。
4 实验
4.1 训练数据集
为了确保网络能够具备充足的脚步声视听数据进行训练,我们对现有的视听数据集如AudioSet等进行了深入的调研和分析。然而,这些数据集无法满足我们对数据的特定要求,尤其是在脚步声领域,其数据量不足且包含大量背景噪声,难以适用于网络的视听学习。因此,我们构建了一个专注于脚步声的全新视听数据集。
我们的脚步声音数据集涵盖了三种类型的运动:步行、跑步和跳跃,以及三种运动方向:直线、圆圈和原地。同时,我们还考虑了四种不同的地板类型,包括地毯、混凝土、木地板和瓷砖。每个视频的平均时长为10秒,总共包含700个视频。
为了确保训练数据集的质量和适用性,我们进行了必要的音频去噪处理,以满足对脚步声细粒度合成的需求,以达到预期的训练效果。该数据集将为我们的研究和网络训练提供坚实的基础。
4.2 实验结果
在本节中,我们对细粒度脚步音效合成方法的同步结果和内容细粒度调整结果进行了展示,并且对本文方法、RegNet[8]、SpecVQGAN[10]、SPMNet[13]等方法以及真实音频进行了主观评价。
针对脚步音效同步效果的实验结果如图4所示,本方法利用视听生成网络学习并捕捉视觉特征,实现视听同步的脚步音效合成,保证视觉和声音之间的时序一致性。从图中可以看出,以真实音频为参考,本文方法的合成音频在音效同步中的关键节点与真实音频一致,真实音频与合成音频的波形图对比可充分体现本文方法的音效同步效果。该结果表明该算法能有效捕捉视听关联,保证视觉和声音的时序一致性。
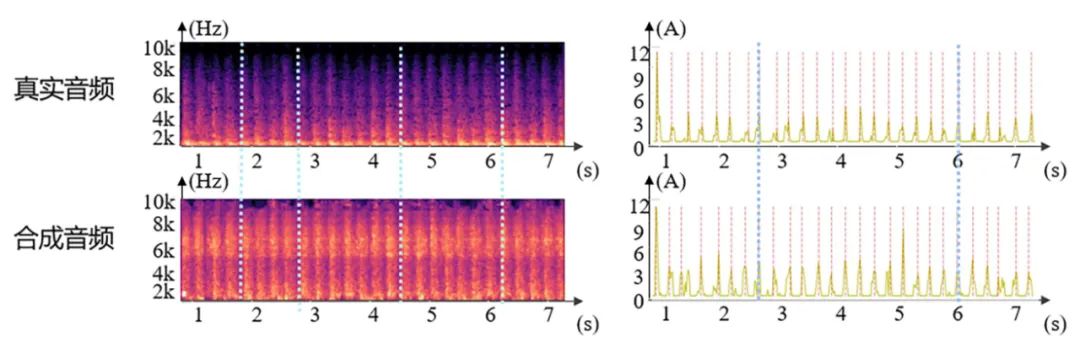
图4 脚步音效同步结果
在内容细粒度调整方面,我们分别针对全局位移与动作调整进行结果展示。针对全局位移调整的实验结果如图5(a)所示,本方法会根据全局位移大小来宏观调整脚步声的响度。从图5(a)可以看出,随着全局位移的变化,脚步声的响度也会呈正比关系变化,以获得根据该位移变化视频模拟的脚步声结果。模拟脚步声波形随时间位移波形变化而改变。该结果表明,该算法能有效把控位移与声音之间的相关性,实现基于人物位移的响度进行细粒度调整,充分模拟真实音效。
针对动作调整的实验结果如图5(b)所示,本方法会根据动作类型与脚步的加速度细粒度地调整脚步声响度大小。如图5(b)所示,当视频中人物呈现跑步动作时,其模拟的脚步声响度较大且频率较快,当视频人物呈现走路动作时,其模拟脚步声响度较小且频率较慢,随着动作的变化,拟声结果变化明显,且与变化方向相吻合。该结果表明该算法能有效学习动作与声音之间的相关性,在响度方面能根据动作与视觉特征实现细粒度调整。
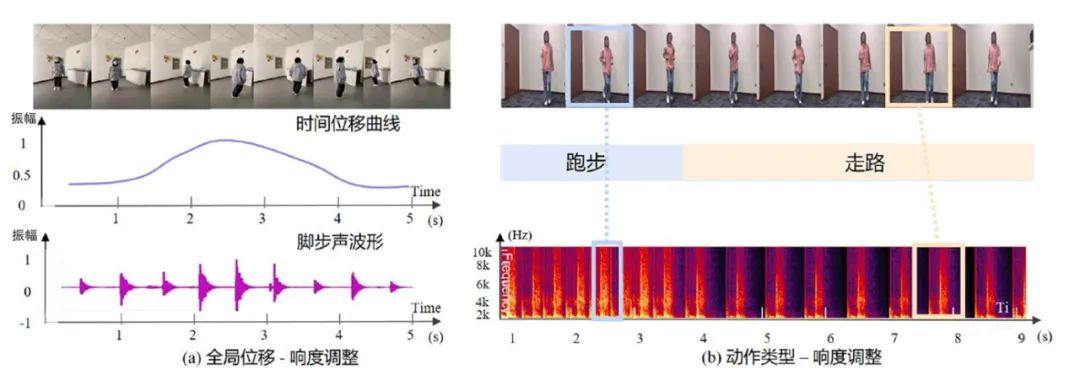
图5 脚步音效内容细粒度优化结果
为了进一步评估本文方法的有效性,我们将本文方法的生成结果与RegNet[8]、SpecVQGAN[10]、SPMNet[13]方法的生成结果以及数据集中真实录制的视频进行了主观评价,参与者将从生成音频的音质、视听同步性能以及视频的整体质量三方面进行评价打分。用户研究结果如图6所示,在用户针对声音质量、同步质量以及整体质量三个方面对于四种方法的评价中,对于本文方法的评价均高于其他方法,仅次于数据集中真实录制的视频效果。该结果表明我们的方法在音质和视听同步方面效果良好。虽然本文方法与真实录音效果还有一定差距,但与现有方法相比,本文方法性能更好,这也证明了我们设计的算法的有效性。
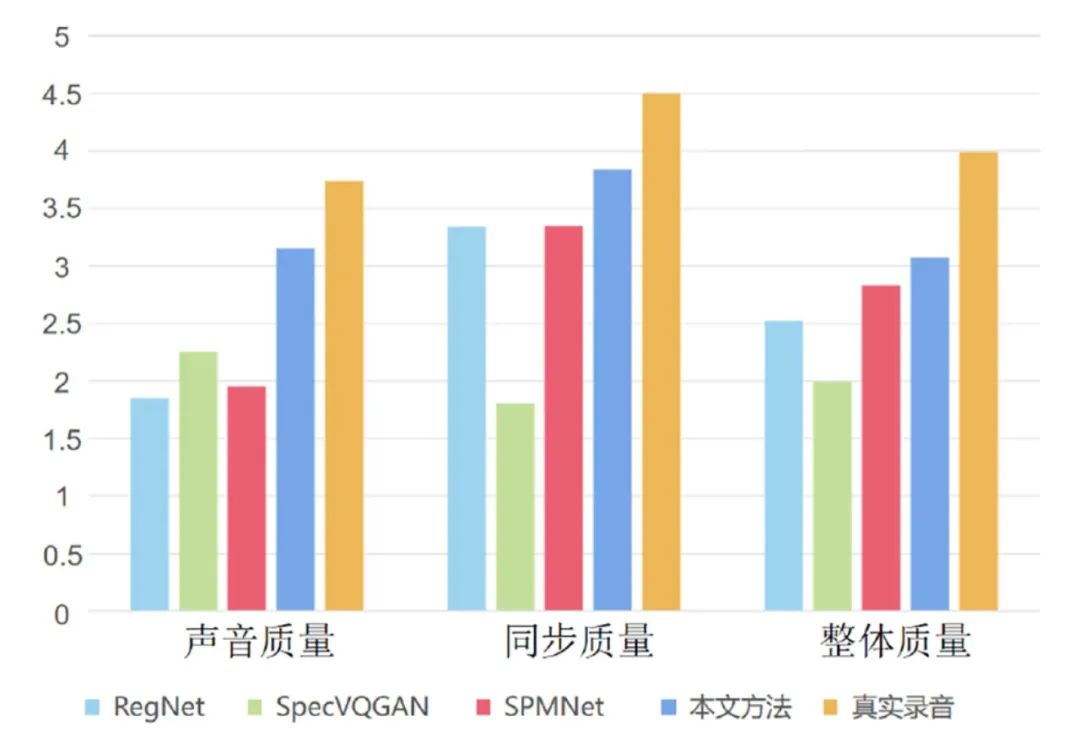
图6 主观评价结果
5 总结
本文提出了一种新颖的视觉引导的细粒度脚步音效合成方法,该方法将数据驱动和规则建模方法集成到视听同步的脚步声合成中,通过两种方法的创新与融合,保证了视听的关联与映射。具体来说,该方法通过数据驱动的音效生成网络能够实现视觉与听觉之间的同步性。同时,本文设计的脚步音效内容细粒度优化模块建立了视觉运动状态、空间位置和脚步声之间的复杂映射关系,实现了根据视觉信息对脚步音效的音色和响度进行参数化控制。此外,为了进一步提高细粒度的脚步声生成效果,本文还构建了一个脚步视听训练数据集。实验结果表明,该方法能够实现在达到视觉听觉同步的同时,合成出具细粒度的视听内容一致的脚步声。在目前电影后期音效配音行业仍然高度依赖人工调整的现状下,本文提出的针对电影脚步音效的自动化配音方案,不仅实现了视听同步性,还保证了内容合理性,能够有效减轻后期音效设计师的压力,并为后期音效制作提供了新的技术思路。
本文方法依然有许多局限性,在未来的工作中仍有待改进。虽然本文的视觉引导细粒度脚步音效合成方法能够进行视觉范围的控制调整,但当视觉脚步发声定位不准确时,本文方法的优势是十分有限的。因此,进一步探索视听映射关系以更稳定地获得更准确的发声时间将是未来的一个研究方向。此外,视觉引导的细粒度脚步音效合成方法只探讨了位移、运动、地面材质和声音之间的映射关系,因此更详细地探索与音效有关的各项其他类型的信息,以合成更加丰富和真实的声音也是一个研究方向。
未来我们需要自主研发更多的创新性算法,从更全面的角度促进电影后期声音合成技术的发展。我们将引入更多先进技术到电影行业中,实现理论与实践相结合,同时也要捕捉现代科学技术的发展趋势,并研发前沿视听技术,努力实现中国电影科技自立自强,积极推动中国电影行业发展进步,实现高质量可持续发展。
参考文献
(向下滑动阅读)
[1] Cardle M, Brooks S, Bar⁃Joseph Z, et al. Sound⁃by⁃numbers: motion⁃driven sound synthesis[C]//Symposium on Computer Animation,2003: 349⁃356.
[2] Marelli D, Aramaki M, Kronland⁃Martinet R, et al. Time⁃frequency synthesis of noisy sounds with narrow spectral components[J]. IEEE transactions on audio, speech, and language processing, 2010, 18(8): 1929⁃1940.
[3] Zhang Z, Raghuvanshi N, Snyder J, et al. Acoustic texture rendering for extended sources in complex scenes[J]. ACM Transactions on Graphics (TOG), 2019, 38(6): 1⁃9.
[4] Liu S, Gao S. Automatic synthesis of explosion sound synchronized with animation[J]. Virtual Reality, 2020, 24(3): 469⁃481.
[5] Schweickart E, James D L, Marschner S. Animating elastic rods with sound[J]. ACM Transactions on Graphics (TOG), 2017, 36(4): 1⁃10.
[6] Liu S, Cheng H, Tong Y. Physically⁃based statistical simulation of rain sound[J]. ACM Transactions on Graphics (TOG), 2019, 38(4): 1⁃14.
[7] Peltola L, Erkut C, Cook P R, et al. Synthesis of hand clapping sounds[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(3): 1021⁃1029.
[8] Chen P, Zhang Y, Tan M, et al. Generating visually aligned sound from videos[J]. IEEE Transactions on Image Processing, 2020, 29: 8292⁃8302.
[9] Liu S, Li S, Cheng H. Towards an end⁃to⁃end visual⁃to⁃raw⁃audio generation with GAN[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 32(3): 1299⁃1312.
[10] Iashin V, Rahtu E. Taming visually guided sound generation[EB/OL]. (2021⁃10⁃17).https://arxiv.org/abs/2110.08791v1.
[11] Ghose S, Prevost J J. Autofoley: Artificial synthesis of synchronized sound tracks for silent videos with deep learning[J]. IEEE Transactions on Multimedia, 2020, 23: 1895⁃1907.
[12] Ghose S, Prevost J J. Foleygan: Visually guided generative adversarial network⁃based synchronous sound generation in silent videos[J]. IEEE Transactions on Multimedia, 2022.
[13] Ma X, Zhong W, Ye L, et al. Visually aligned sound generation via sound⁃producing motion parsing[J]. Neurocomputing, 2022, 492: 1⁃15.
[14] Schmidhuber J, Hochreiter S. Long short⁃term memory[J]. Neural Comput, 1997, 9(8): 1735⁃1780.
[15] Isola P, Zhu J Y, Zhou T, et al. Image⁃to⁃image translation with conditional adversarial networks[C]// Proceedings of the IEEE conference on computer vision and pattern recognition,2017: 1125⁃1134.
[16] Griffin D, Lim J. Signal estimation from modified short⁃time Fourier transform[J]. IEEE Transactions on acoustics, speech, and signal processing, 1984, 32(2): 236⁃243.
[17] Oord A, Dieleman S, Zen H, et al. Wavenet: A generative model for raw audio[EB/OL]. (2016⁃09⁃19).https://arxiv.org/pdf/1609.03499.pdf.
[18] Kumar K, Kumar R, De Boissiere T, et al. Melgan: Generative adversarial networks for conditional waveform synthesis[J]. Advances in neural information processing systems, 2019, 32.
[19] Kong J, Kim J, Bae J. Hifi⁃gan: Generative adversarial networks for efficient and high fidelity speech synthesis[J]. Advances in Neural Information Processing Systems, 2020, 33: 17022⁃17033.
[20] Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]// International conference on machine learning. PMLR, 2019: 6105⁃6114.
