《现代电影技术》丨基于深度学习的电影数字修复系统研究
本文刊发于《现代电影技术》2023年第8期
专家点评
未来,人工智能在影像修复和内容生成领域将发挥重要作用,具有显著的应用价值。在影像修复领域,人工智能可以通过学习图像的特征和上下文信息,填补缺失像素和恢复受损细节,实现对受损图像的自动修复,进而完成智能修复和重建我们的视觉影像记忆。在内容生成领域,人工智能的能力甚至更为惊人,它能够生成逼真的图像内容,包括超分辨率重建、图像合成和风格化等。这种能力不仅在电影、游戏和设计等领域创造出色的视觉效果,同时在艺术创作中发挥了智慧助手角色,为创作者提供灵感和创作的起点。人工智能应用于影像领域将提升图像质量、丰富创意,为我们带来前所未有的机遇和突破,这不仅推动了电影技术的发展和进步,也为我们的视觉影像艺术开辟了新的可能性。《基于深度学习的电影数字修复系统研究》一文首先介绍了电影修复的必要性和当前面临的挑战,其次详细阐述了基于深度学习的电影数字修复系统研究,包括基于注意力循环时间聚合网络的污损去除算法和基于Transformer的大面积缺失补全算法。该研究对于相关研究和技术人员具有一定的参考价值。
——沈浩
教授、博士生导师
中国传媒大学媒体融合与传播国家重点实验室大数据研究中心首席科学家
作 者 简 介

于冰
上海大学上海电影学院讲师,硕士生导师,主要研究方向:图形图像处理、数字影视技术等。
上海大学上海电影学院硕士研究生在读,主要研究方向:电影修复技术。

陈佳辉

范正辉
上海大学上海电影学院硕士研究生在读,主要研究方向:电影修复技术、深度学习。
上海大学上海电影学院硕士研究生在读,主要研究方向:电影修复技术、深度学习。

相雪

黄东晋
上海大学上海电影学院副教授,博士生导师,主要研究方向:人工智能、影视技术、计算机图形学等
上海大学上海电影学院教授,博士生导师,主要研究方向:数字影视技术、计算机图形学等。

丁友东
摘要
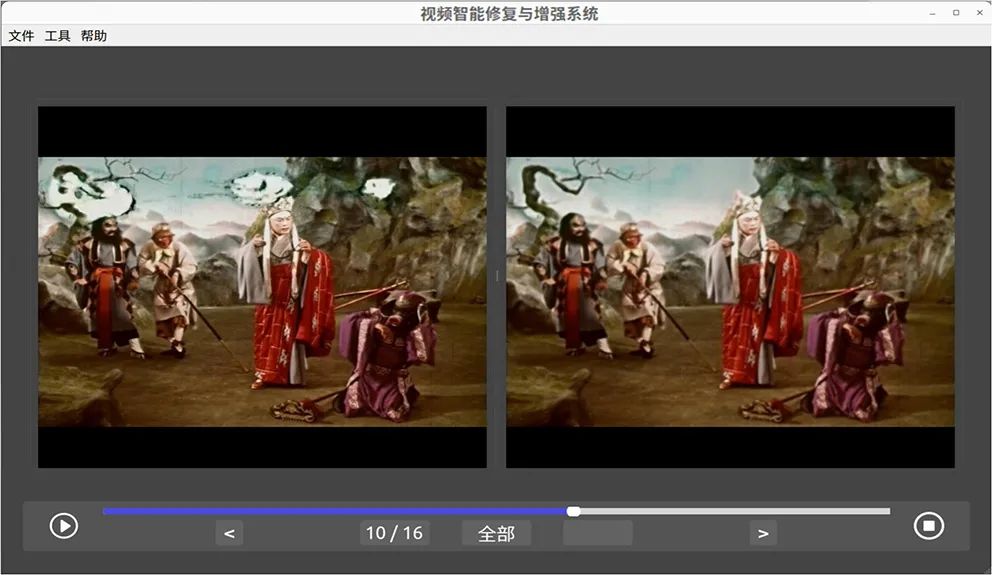
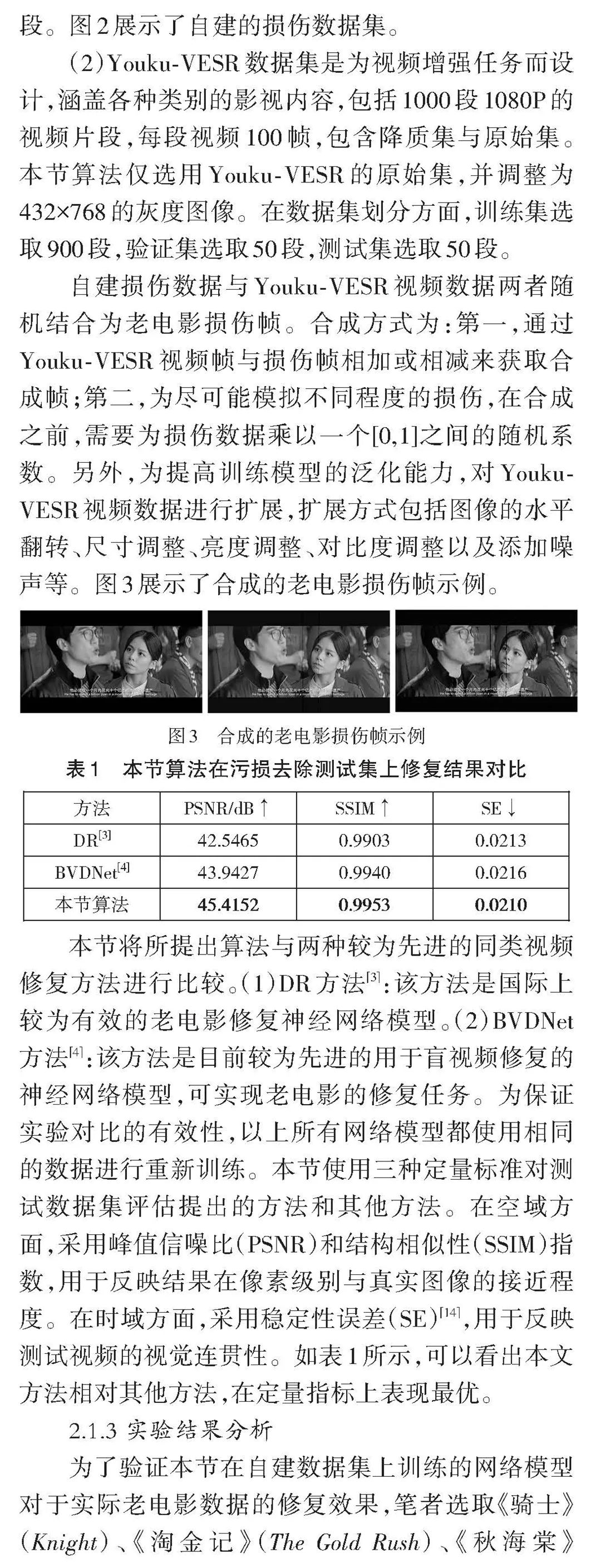
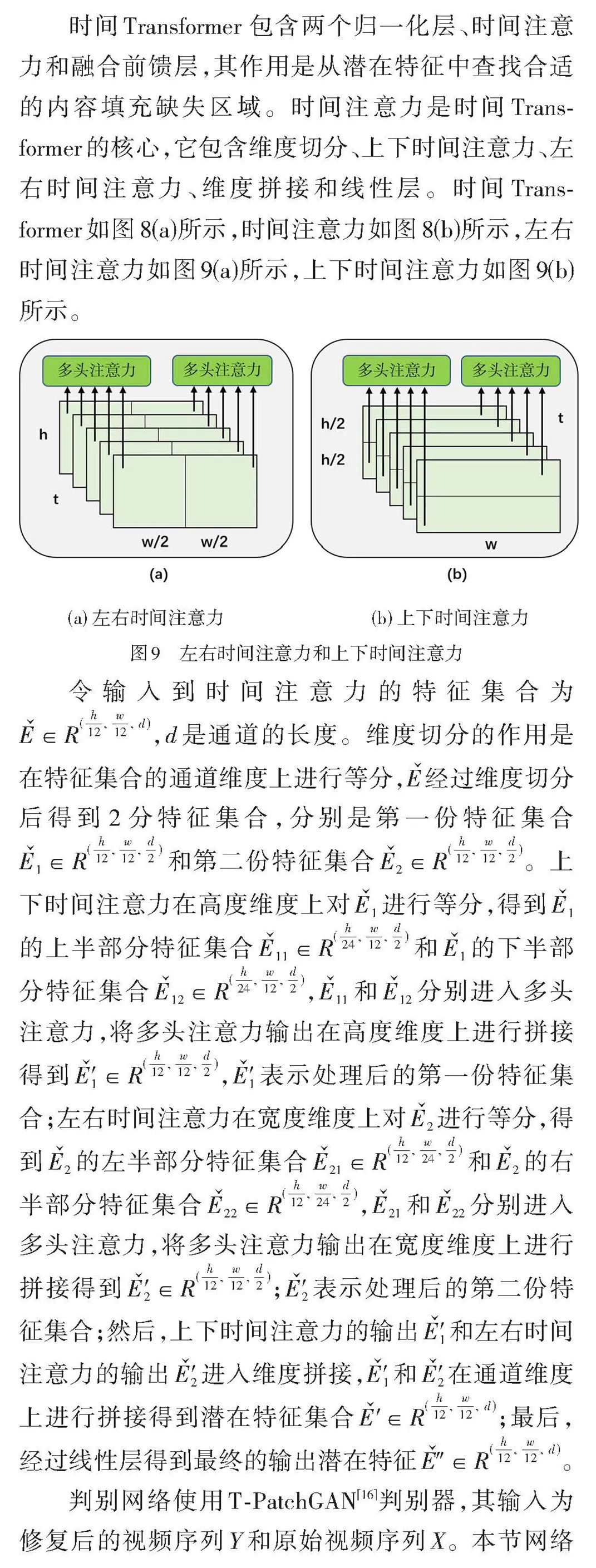
电影智能化升级是电影产业发展的必然趋势,为探索人工智能技术在影像保护领域中的应用,本文基于生成式对抗网络(GAN)、Transformer等深度学习模型,研究去污损、缺失补全等电影修复算法,通过搭建智能化修复平台,实现电影序列去闪烁、去抖动、去噪、去污损、缺失补全、超分辨率增强、帧率提升、黑白上色等功能。实验表明,本文研发的系统能够有效实现电影的智能修复。
关键词
人工智能;深度学习;电影修复;电影增强




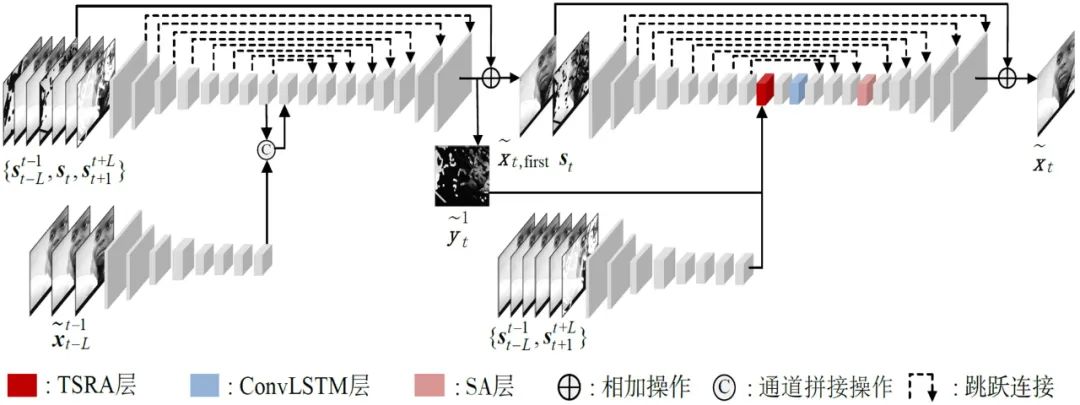
图1 基于注意力循环时间聚合网络的电影污损修复框架









参考文献
(向下滑动阅读)
[1] 中影股份. 中影基地电影核心科技新突破——“中影·神思”人工智能图像处理系统[EB/OL]. (2018⁃12⁃17)[2023⁃06⁃30]. https://www.chinafilm.com/zydt/7077.jhtml.
[2] 爱奇艺. 高分经典老片还能焕发新生?爱奇艺ZoomAI修复让用户“看清”上百部经典[EB/OL]. (2021⁃07⁃01)[2023⁃06⁃30]. https://www.iqiyi.com/kszt_phone/news20210701.html.
[3] Kim D, Woo S, Lee J Y, et al. Recurrent temporal aggregation framework for deep video inpainting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(5): 1038⁃1052.
[4] Iizuka S , Simo-Serra E . DeepRemaster: temporal source-reference attention networks for comprehensive video enhancement[J]. ACM Transactions on Graphics, 2019, 38(6): Article No 196.
[5] Zeng Y, Fu J, Chao H. Learning joint spatial⁃temporal transformations for video inpainting[C]//European Conference on Computer Vision. Springer, Cham, 2020: 528⁃543.
[6] Liu R, Deng H, Huang Y, et al. Decoupled spatial⁃temporal transformer for video inpainting[EB/OL].(2021⁃04⁃14)[2023⁃06⁃30]. https://arxiv.org/abs/2104.06637v1
[7] Liu R, Deng H, Huang Y, et al. Fuseformer: Fusing fine⁃grained information in transformers for video inpainting[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 14040⁃14049.
[8] Lai W, Huang J, Wang O, et al. Learning blind video temporal consistency[C]//European Conference on Computer Vision, 2018: 179⁃195.
[9] Iizuka S, Simo⁃Serra E. DeepRemaster: temporal source⁃reference attention networks for comprehensive video enhancement[J]. ACM Transactions on Graphics, 2019, 38(6).
[10] Wang T C, Liu M Y, Zhu J Y, et al. High⁃resolution image synthesis and semantic manipulation with conditional GANs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 8798⁃8807.
[11] Kingma D P, Ba J. Adam: a method for stochastic optimization[EB/OL].(2017⁃01⁃30) [2023⁃06⁃30].https://arxiv.org/abs/1412.6980.
[12] Chen J, Tan X, Shan C, et al. VESR⁃Net: the winning solution to youku video enhancement and super⁃resolution challenge[EB/OL]. (2020⁃03⁃04) [2023⁃06⁃30].https://arxiv.org/abs/2003.02115.
[13] Liu G L, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of European Conference on Computer Vision,2018: 89⁃105.
[14] Chen D D, Liao J, Yuan L, et al. Coherent online video style transfer[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1114⁃112.
[15] Liu R, Deng H, Huang Y, et al. Decoupled spatial⁃temporal transformer for video inpainting[EB/OL].(2021⁃04⁃14)[2023⁃06⁃30]. https://arxiv.org/abs/2104.06637.
[16] Chang Y L, Liu Z Y, Lee K Y, et al. Free⁃form video inpainting with 3d gated convolution and temporal patchgan[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision,2019: 9066⁃9075.
[17] Xu N, Yang L, Fan Y, et al. Youtube⁃vos: A large⁃scale video object segmentation benchmark[EB/OL]. (2018⁃09⁃06)[2023⁃06⁃30]. https://arxiv.org/abs/1809.03327.
[18] Perazzi F, Pont⁃Tuset J, McWilliams B, et al. A benchmark dataset and evaluation methodology for video object segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2016: 724⁃732.
[19] 陈钰,丁友东,于冰,等.基于像素流的视频彩色化[J].上海大学学报(自然科学版),2021,27(01):18⁃27.
[20] Lei C, Ren X, Zhang Z, et al. Blind Video Deflickering by Neural Filtering with a Flawed Atlas[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2023: 10439⁃10448.
[21] Xu Y, Zhang J, Maybank S J, et al. Dut: Learning video stabilization by simply watching unstable videos[J]. IEEE Transactions on Image Processing, 2022, 31: 4306⁃4320.
[22] Claus M, Van Gemert J. Videnn: Deep blind video denoising[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops,2019: 1⁃10.
[23] Huang Z W, Zhang T Y, Heng W, et al. Real⁃Time Intermediate Flow Estimation for Video Frame Interpolation[EB/OL]. (2021⁃11⁃17)[2023⁃06⁃30]. https://arxiv.org/pdf/2011.06294.pdf.
[24] Chan K C K, Wang X, Yu K, et al. Basicvsr: The search for essential components in video super⁃resolution and beyond[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition,2021: 4947⁃4956.
【本文项目信息】上海市人才发展资金项目(2021016)。
