百度指数和票房的傻瓜模型
百度指数和票房的傻瓜模型
文章 & 制图:Snow雪子。微信号jidan201212
数据:兰思逸
“傻瓜”不是贬义,是好用的意思,像傻瓜相机一样;也有简单之意,因为这个模型的原理相对简单,数据也很基本,就是每部电影的公开的百度指数以及他们的最终票房。
在工作中,经常问到的问题是,这个片子票房要到XX,那么KPI应该怎么拆解?或者反过来,百度指数已经达到这个数值,代表了什么?说明了什么?这其实需要一个基准,判断标准。
年中我在写一篇“电影小数据的价值”文章中,提到Variety利用四个公开数据源(Facebook, Twitter, YouTube和Google)预测票房的事。比如,一部电影在上映前一个时间点的粉丝数量、提及数量、视频播放数量或者搜索数量,与它类似的片子的数据基准做对比,得出表现是否优劣以及票房表现预测如何的结论。
这篇文章的核心意思是,虽然能够利用技术深入挖掘数据最好,但是光杆司令的情况下,也是可以做出一些东西的。并且基于目前的市场情况,利用公开数据的是绝大多数,包括KPI的制定也是基于公开数据的结果。
回到开头提到的那两个问题,实际上也就是研究公开的百度指数与票房的关系。在KPI拆分上,百度指数是一个集大成的指标,反映了宣传的整体效果。
1. 模型概论
我们采用了2013年1月1日至2014年9月18日期间所有上映的最终票房超过5000万的影片。刨去无效的样本,比如《反贪风暴》这种临时调档,《爸爸去哪儿》这种电影和电视剧百度指数混为一体的特殊案例,共有134部影片。
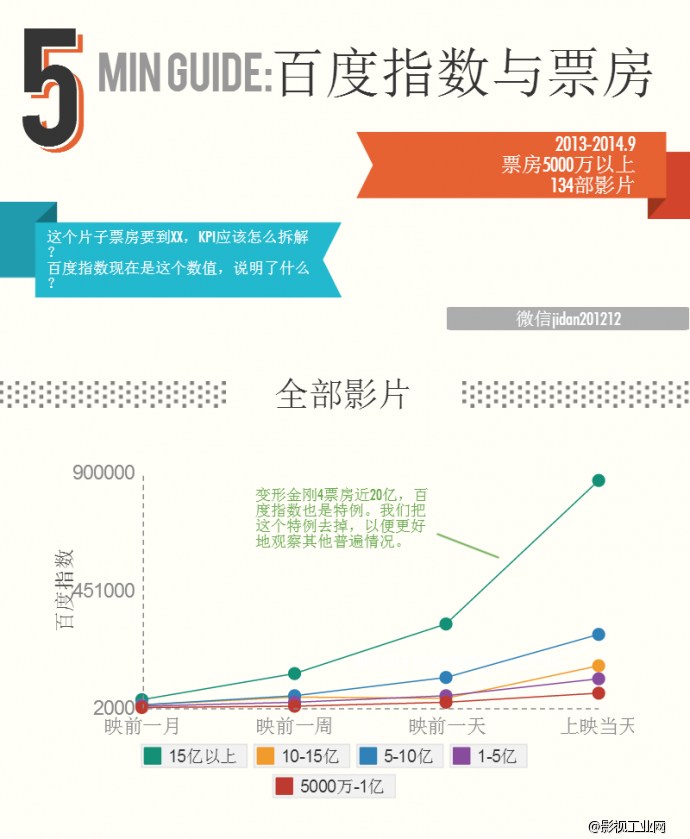
我们按照票房高低做了五个档次:票房超过15亿的影片,10-15亿的,5-10亿的,1-5亿的,5000万-1亿的。
每部影片我们按照四个时间节点做了百度指数的统计:映前一个月、映前一周、映前一天和上映当天。其中,映前一月和一周的指数,并不是某一天的节点数据,因为这样有偏见的嫌疑,比如那一天恰好有大事出现。并且,这两个数据也不应该是平均数。因为数据是要解答“如果票房要达到XX,映前一个月应该达到什么数值”的问题,而平均数算入了整个周期的情况,给出了偏高的不正确的值。
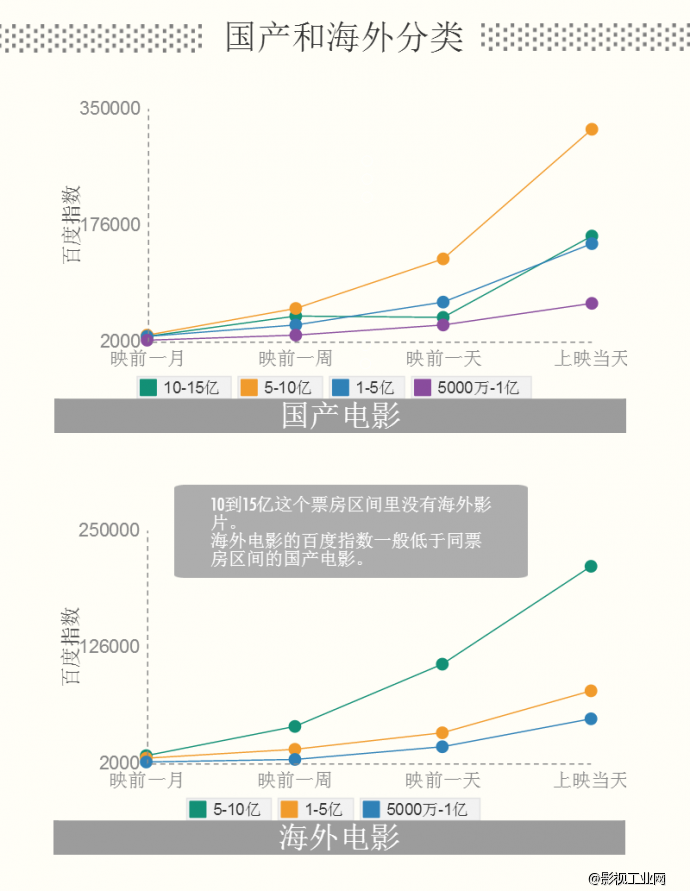
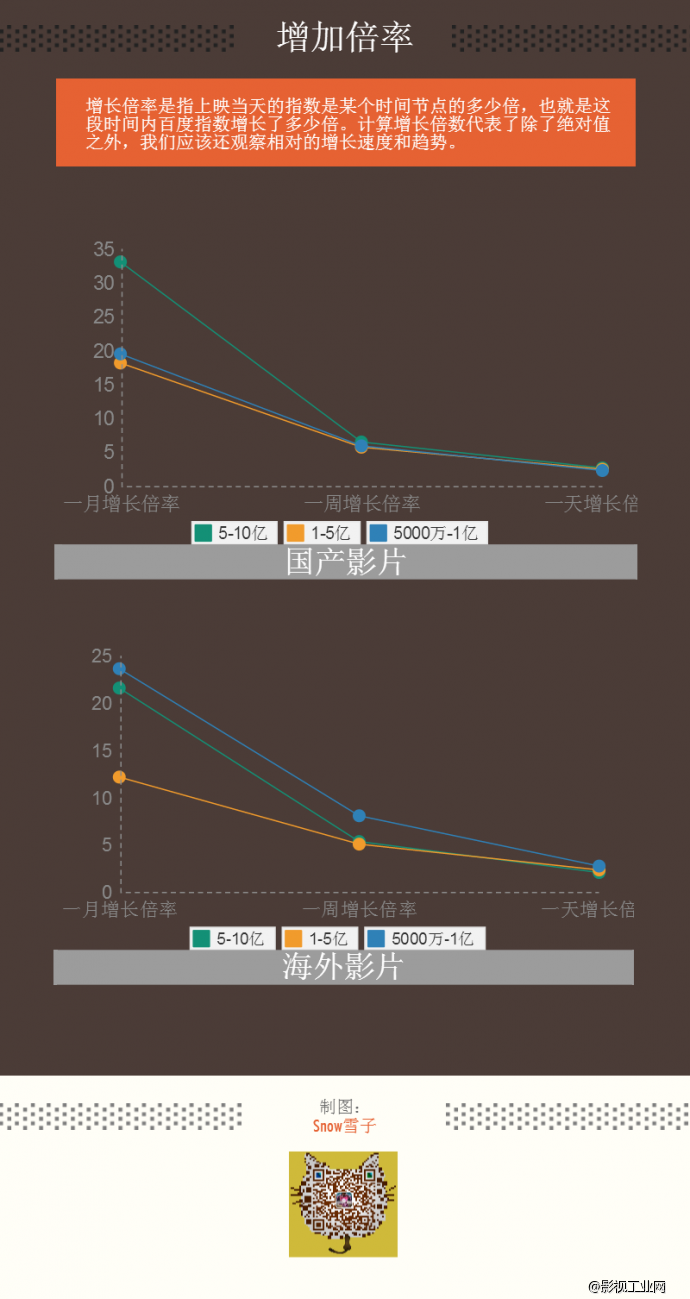
除了按照票房档位分类,我们还在每一个票房档内部按照国产/海外做了分类。香港、台湾电影和他们与内地的合拍片我们算进了“国产”。
2. 模型结果
3. 模型局限和日后发展
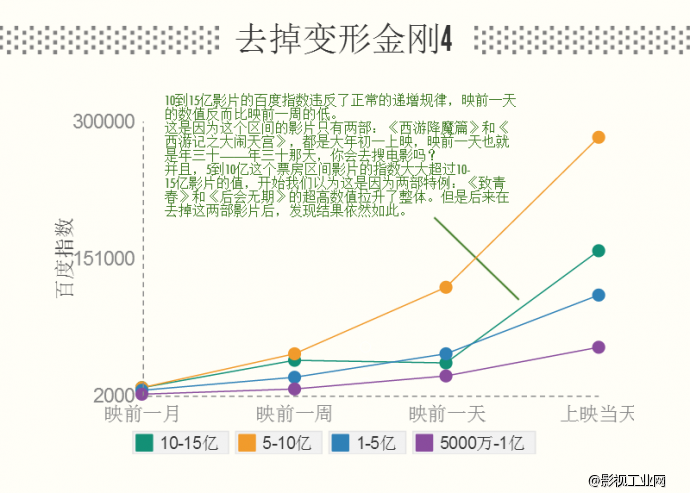
首先,此次研究的样本量有限,特别是5亿以上的影片。样本稀少的情况导致了特殊案例对整体结果的突出影响。比如5-10亿的电影只有10部,其中《致青春》和《后会无期》的指数都因为例如导演就是社交网络大号的关系而非常之高,甚至超过票房更高影片的数值,这就直接拉高了这一票房档位的结果。如果样本量相对较大,那么个别的特殊情况会被更多的普遍情况中和,从而减少偏见性影响。
目前的样本量跟我们只截取了13年开始这个时间段有关系,也看出来5亿以上的影片并不多。我们并没有继续选择13年之前的数据,因为市场变化太大,12年的表现对当下已没有那么大的参考意义。这也意味着此项研究需要继续下去,长期监测,不断调整。
其次,影片档期这个因素并没有考虑进来,而这个因素和票房有着直接的联系。其实,这个傻瓜模型是基础的,但是是迈出了第一步。在利用历史数据做判断的时候,除了票房这个刚性判断标准外,还有影片量级、主创、类型、档期等参考因素。本模型并没有如此细致。建议使用过程中,可以以票房档位-百度指数做起点,再深入挑选几部具体的影片做参考。
如想进一步完善,持续的研究是唯一途径。
文章 & 制图:Snow雪子。微信号jidan201212
数据:兰思逸
“傻瓜”不是贬义,是好用的意思,像傻瓜相机一样;也有简单之意,因为这个模型的原理相对简单,数据也很基本,就是每部电影的公开的百度指数以及他们的最终票房。
在工作中,经常问到的问题是,这个片子票房要到XX,那么KPI应该怎么拆解?或者反过来,百度指数已经达到这个数值,代表了什么?说明了什么?这其实需要一个基准,判断标准。
年中我在写一篇“电影小数据的价值”文章中,提到Variety利用四个公开数据源(Facebook, Twitter, YouTube和Google)预测票房的事。比如,一部电影在上映前一个时间点的粉丝数量、提及数量、视频播放数量或者搜索数量,与它类似的片子的数据基准做对比,得出表现是否优劣以及票房表现预测如何的结论。
这篇文章的核心意思是,虽然能够利用技术深入挖掘数据最好,但是光杆司令的情况下,也是可以做出一些东西的。并且基于目前的市场情况,利用公开数据的是绝大多数,包括KPI的制定也是基于公开数据的结果。
回到开头提到的那两个问题,实际上也就是研究公开的百度指数与票房的关系。在KPI拆分上,百度指数是一个集大成的指标,反映了宣传的整体效果。
1. 模型概论
我们采用了2013年1月1日至2014年9月18日期间所有上映的最终票房超过5000万的影片。刨去无效的样本,比如《反贪风暴》这种临时调档,《爸爸去哪儿》这种电影和电视剧百度指数混为一体的特殊案例,共有134部影片。
我们按照票房高低做了五个档次:票房超过15亿的影片,10-15亿的,5-10亿的,1-5亿的,5000万-1亿的。
每部影片我们按照四个时间节点做了百度指数的统计:映前一个月、映前一周、映前一天和上映当天。其中,映前一月和一周的指数,并不是某一天的节点数据,因为这样有偏见的嫌疑,比如那一天恰好有大事出现。并且,这两个数据也不应该是平均数。因为数据是要解答“如果票房要达到XX,映前一个月应该达到什么数值”的问题,而平均数算入了整个周期的情况,给出了偏高的不正确的值。
除了按照票房档位分类,我们还在每一个票房档内部按照国产/海外做了分类。香港、台湾电影和他们与内地的合拍片我们算进了“国产”。
2. 模型结果
3. 模型局限和日后发展
首先,此次研究的样本量有限,特别是5亿以上的影片。样本稀少的情况导致了特殊案例对整体结果的突出影响。比如5-10亿的电影只有10部,其中《致青春》和《后会无期》的指数都因为例如导演就是社交网络大号的关系而非常之高,甚至超过票房更高影片的数值,这就直接拉高了这一票房档位的结果。如果样本量相对较大,那么个别的特殊情况会被更多的普遍情况中和,从而减少偏见性影响。
目前的样本量跟我们只截取了13年开始这个时间段有关系,也看出来5亿以上的影片并不多。我们并没有继续选择13年之前的数据,因为市场变化太大,12年的表现对当下已没有那么大的参考意义。这也意味着此项研究需要继续下去,长期监测,不断调整。
其次,影片档期这个因素并没有考虑进来,而这个因素和票房有着直接的联系。其实,这个傻瓜模型是基础的,但是是迈出了第一步。在利用历史数据做判断的时候,除了票房这个刚性判断标准外,还有影片量级、主创、类型、档期等参考因素。本模型并没有如此细致。建议使用过程中,可以以票房档位-百度指数做起点,再深入挑选几部具体的影片做参考。
如想进一步完善,持续的研究是唯一途径。
本文为作者 Snow雪子 分享,影视工业网鼓励从业者分享原创内容,影视工业网不会对原创文章作任何编辑!如作者有特别标注,请按作者说明转载,如无说明,则转载此文章须经得作者同意,并请附上出处(影视工业网)及本页链接。原文链接 https://cinehello.com/stream/54883
